Jordan Regan
Data Engineer
Background
I started as a student passionate about sciences, driven by a curiosity for how the world works. During a challenging period in my life, I discovered the beauty of programming - not just as a skill, but as a turning point in my life that enabled newfound creativity and innovation. About six months later I was engineering large-scale batch data processes and administrating a Google Cloud Platform data warehouse for a company of thousands of employees - there was no going back now!
After a couple of years of data engineering, I was able to take the opportunity to learn enterprise backend development, which led me down new avenues in the world of data: real-time, event streaming with Kafka; federated GraphQL queries with Apollo; and learning all about project data requirements in everything from CRM integration to enterprise microservice architecture.
Four years into my data engineering journey and I am an accomplished cloud and on-prem pipeline aficionado with an ever-abounding thirst for knowledge and efficiency and a constantly developing background of maths and science on which to operate. Having found my footing in the more advanced areas of development such as: CI/CD; IaC; dependency management; parallel processing and the dreaded stakeholder management, to name a few, I now find myself in a position of confidence where the only blocker left standing in the way of my everyday work... is time.
As I prepare for a future defined by larger data volumes and AI powered processes, I have been skilling up in those data engineer techniques which serve as precursors to machine learning modelling. In the big-data front, I have gained hands-on experience with optimising high-throughput systems, as well as managing big-data clusters in AWS. In relation to machine learning directly, vector-indexing for semantic searches, data cleaning and preprocessing, and developing AI agents with integrated LLM wrappers and context management, are just some of the areas where I have been honing my skills to develop readiness for a world where data pipelines are inextricable from artificial intelligence.
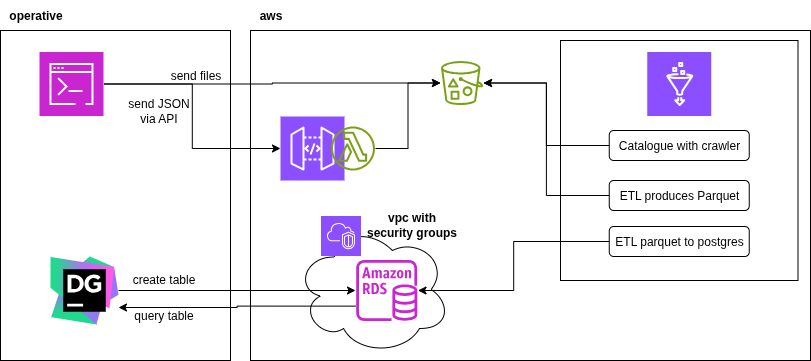
AWS Glue Hardware Correlation ETL
End-to-end data flow in AWS Glue to ingest and process data from multiple sources mimicking real-world hardware logs and structured business data. Final outcome is structured, analytics ready data in an RDS PGSQL instance.
- AWS Glue (ETL, Data Connection, Crawlers)
- AWS (RDS, API Gateway, Lambda)
- VPC/Security Groups
- Python/PySpark
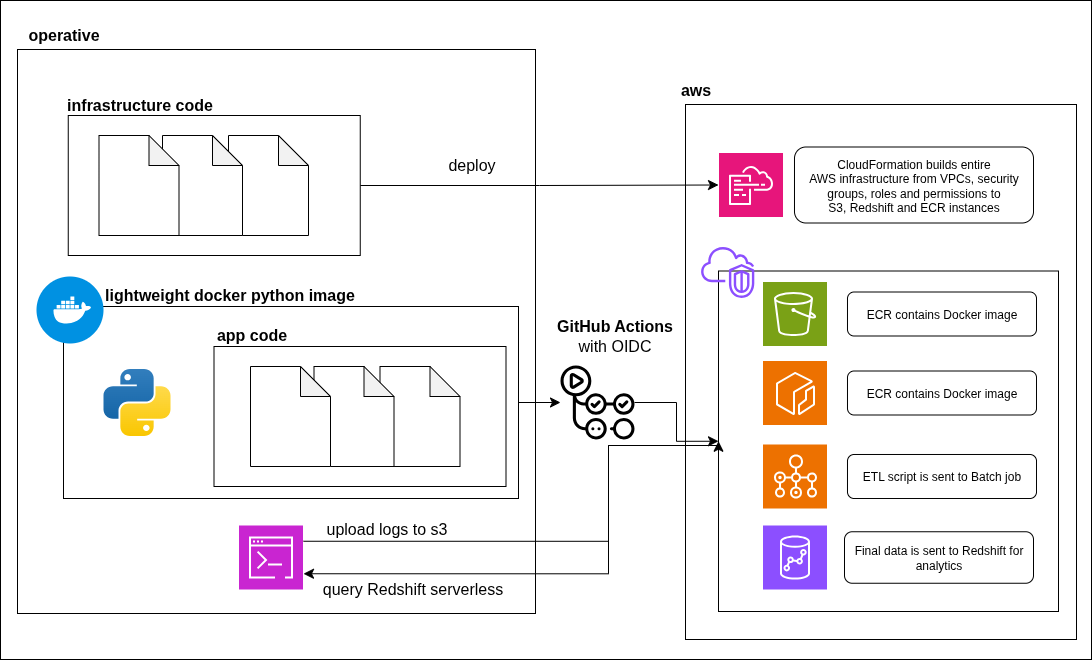
AWS Batch with Docker & CI/CD
A comprehensive, end-to-end data pipeline built on a serverless architecture. This project uses AWS Batch to run containerized Python ETL jobs on on S3 log data, loading aggregated results into a Redshift Serverless data warehouse. The entire cloud environment is defined using Infrastructure as Code (CloudFormation), and a GitHub Actions workflow provides full CI/CD automation, using OIDC for secure, keyless authentication to AWS.
- AWS Glue (Batch, Redshift, S3, ECR)
- CloudFormation (IaC)
- GitHub Actions (CI/CD, OIDC)
- Docker
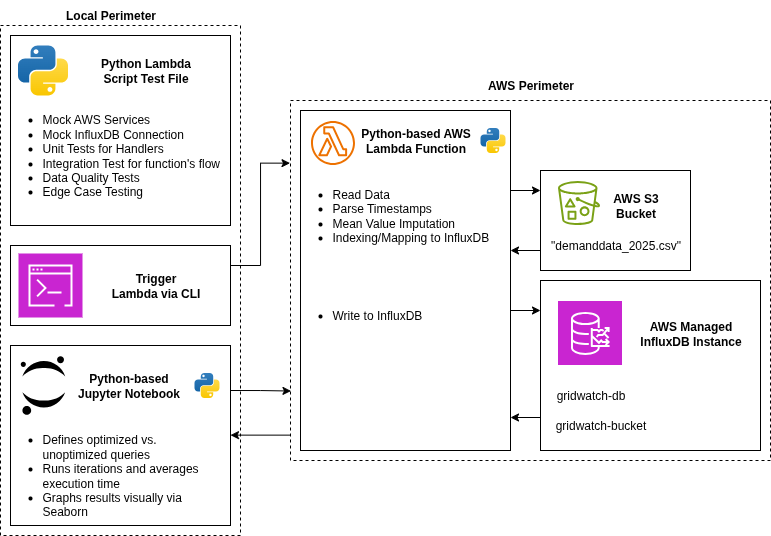
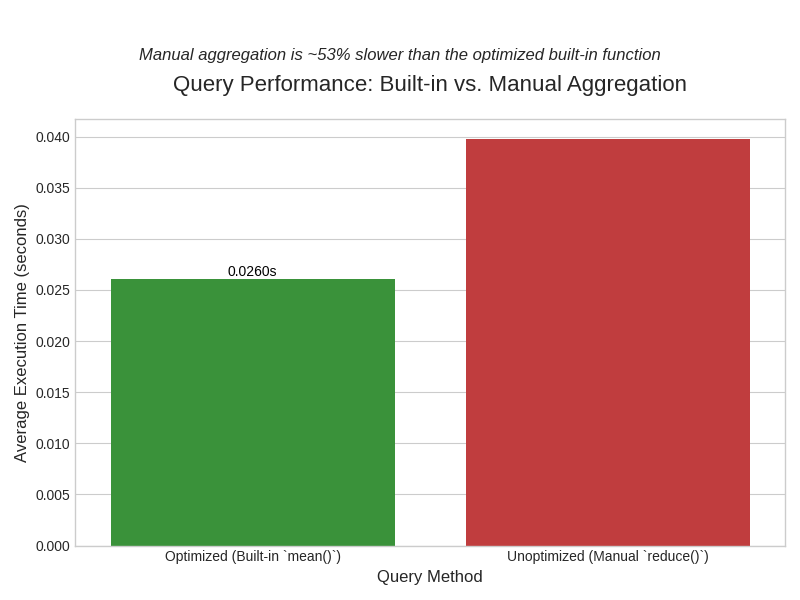
AWS Timestream Query Optimization
A proof of concept for an AWS architected time-series data ingestion with AWS Timestream (InfluxDB) and a remotely controlled Python-based Lambda Script. Also features a simple example of benchmarking optimized vs. poorly optimized queries showing a potential for a 35% decrease in query overheads.
- AWS (S3, ECR, Lambda)
- Timestream/InfluxDB
- Python/SQL
- Data Cleaning
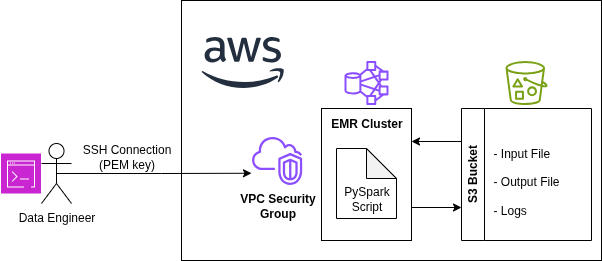
Distributed Processing in Spark & Hadoop
Safe and production-ready, distributed data processing pipeline using Apache Spark on AWS EMR, with managed VPC and SSH for secure access. This project involved processing Amazon's extremely large public product dataset, transforming it efficiently and scalably with Spark, and storing the results in S3.
- AWS (S3, EMR, VPC)
- Spark
- Python
- SQL
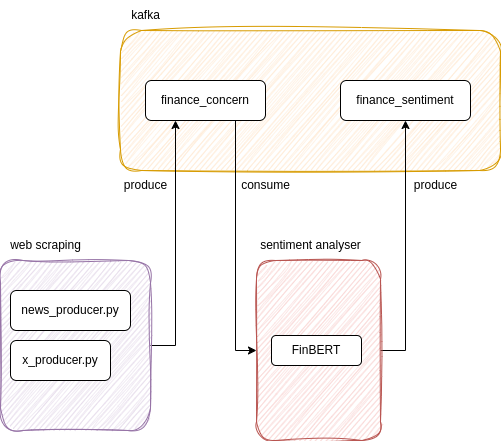
Financial Sentiment Analysis & Web Scraping with Kafka
This application allows the data engineer to easily set up new Kafka producer clients to ingest financial data from a number of public sources on a schedule. Once ingested, the events are propagated through the system in real-time and run through a FinBERT sentiment analysis model before being distributed again with Kafka.
- Kafka
- FinBERT
- Python
- Scheduling
Have a project in mind?
Let's build something great together. Reach out and let's start the conversation.